陈天奇的MLC课程,参考
1.概述#
定义:将机器学习的算法(模型)从开发形式(如pytorch、tf等通用框架编写的模型描述以及相关权重),通过变换和优化,转化为部署形式(如模型支撑代码、内存控制、接口等) 即,将神经网络模型转变成在特定硬件上运行的张量函数代码
机器学习编译目标:
- 集成和最小化依赖
- 利用硬件加速:利用到每个部署环境的原生加速技术
- 通用优化
2. 张量程序抽象#
元张量函数:机器学习模型执行中的每一个步骤(或者说算子?),如linear、relu、softmax
许多不同的抽象可以表达同一种元张量函数,如torch.add和numpy.add,同时,有些机器学习框架也提供模型的编译过程优化,将元张量函数转变成更专门的、针对性的函数
张量程序抽象:一个典型的元张量函数实现包括:
- 存储数据的多维数组
- 驱动张量计算的循环嵌套
- 计算语句
根据抽象出来的共同特征,元张量函数因此可以被一系列有效的程序变换所改变,即优化。 一般情况下,我们感兴趣的大部分元张量函数都具有良好的可变换属性。
TensorIR:TVM使用的张量程序抽象#
前提:大多数的机器学习编译可以视为张量函数之间的变换
示例:一个经典的点积 + relu 网络#
dtype = "float32"
a_np = np.random.rand(128, 128).astype(dtype)
b_np = np.random.rand(128, 128).astype(dtype)
c_mm_relu = np.maximum(a_np @ b_np, 0)在底层,numpy可能使用循环和算术运算实现上述操作:
def lnumpy_mm_relu(A: np.ndarray, B: np.ndarray, C: np.ndarray):
# 存储数据的多维数组
Y = np.empty((128, 128), dtype="float32")
# 驱动张量计算的循环嵌套
for i in range(128):
for j in range(128):
for k in range(128):
if k == 0:
Y[i, j] = 0
# 计算语句
Y[i, j] = Y[i, j] + A[i, k] * B[k, j]
# 驱动张量计算的循环嵌套
for i in range(128):
for j in range(128):
# 计算语句
C[i, j] = max(Y[i, j], 0)TensorIR实现:#
@tvm.script.ir_module
class MyModule:
@T.prim_func
def mm_relu(A: T.Buffer((128, 128), "float32"),
B: T.Buffer((128, 128), "float32"),
C: T.Buffer((128, 128), "float32")):
T.func_attr({"global_symbol": "mm_relu", "tir.noalias": True})
# 存储数据的多维数组(缓冲区)
Y = T.alloc_buffer((128, 128), dtype="float32")
# 驱动张量计算的循环嵌套
for i, j, k in T.grid(128, 128, 128):
# 计算语句
with T.block("Y"):
vi = T.axis.spatial(128, i)
vj = T.axis.spatial(128, j)
vk = T.axis.reduce(128, k)
with T.init():
Y[vi, vj] = T.float32(0)
Y[vi, vj] = Y[vi, vj] + A[vi, vk] * B[vk, vj]
# 驱动张量计算的循环嵌套
for i, j in T.grid(128, 128):
# 计算语句
with T.block("C"):
vi = T.axis.spatial(128, i)
vj = T.axis.spatial(128, j)
C[vi, vj] = T.max(Y[vi, vj], T.float32(0))ir_module是TVM编译的最小完整单元,在TVM前端,其通常包括一个或多个relay(一个relay通常对应一个端到端模型),在经过如autoTVM、tirPasses之后relay被分解成一个或多个primFunc
块是tensorIR的基本计算单位。定义如下:
[block_axis] = T.axis.[axis_type]([axis_range], [mapped_value])如vi = T.axis.spatial(128, i) 即表示vi为i的映射,范围为(0,128),且该块轴属性为spatial(空间轴),而vk的属性则为reduce规约轴。(可以理解为空间轴是原本就在的,规约轴是在上面做滑动的)
块轴加属性的好处是使得vi,vj,vk独立于外部的循环嵌套i,j,k,同时也对外部循环正确性做了二次验证。同时这些附加信息也有助于机器学习编译分析,比如说,我们总是可以在空间轴上做并行化,但在规约轴上做并行化则需要特定的策略
如果觉得自定义属性比较麻烦也可以一键绑定# SSR means the properties of each axes are "spatial", "spatial", "reduce"
vi, vj, vk = T.axis.remap("SSR", [i, j, k])tensorIR的元张量函数变换#
tensorIR引入了名为Schedule的辅助结构,允许我们进行方便的元张量函数变换
这是原来的:
import IPython
IPython.display.Code(MyModule.script(), language="python")
# from tvm.script import ir as I
# from tvm.script import tir as T
@I.ir_module
class Module:
@T.prim_func
def mm_relu(A: T.Buffer((128, 128), "float32"), B: T.Buffer((128, 128), "float32"), C: T.Buffer((128, 128), "float32")):
T.func_attr({"global_symbol": "mm_relu", "tir.noalias": True})
# with T.block("root"):
Y = T.alloc_buffer((128, 128))
for i, j, k in T.grid(128, 128, 128):
with T.block("Y"):
vi, vj, vk = T.axis.remap("SSR", [i, j, k])
T.reads(A[vi, vk], B[vk, vj])
T.writes(Y[vi, vj])
with T.init():
Y[vi, vj] = T.float32(0)
Y[vi, vj] = Y[vi, vj] + A[vi, vk] * B[vk, vj]
for i, j in T.grid(128, 128):
with T.block("C"):
vi, vj = T.axis.remap("SS", [i, j])
T.reads(Y[vi, vj])
T.writes(C[vi, vj])
C[vi, vj] = T.max(Y[vi, vj], T.float32(0))使用Schedule进行变换:
## 以给定的module作为输入的辅助Schedule类
sch = tvm.tir.Schedule(MyModule)
# 获取对应的块及相应循环的引用
block_Y = sch.get_block("Y", func_name="mm_relu")
i, j, k = sch.get_loops(block_Y)
# 变换:将原有的j循环拆分成两个循环(4表示内部循环长度)
j0, j1 = sch.split(j, factors=[None, 4])
# 再次检查结果
IPython.display.Code(sch.mod.script(), language="python")
@I.ir_module
class Module:
@T.prim_func
def mm_relu(A: T.Buffer((128, 128), "float32"), B: T.Buffer((128, 128), "float32"), C: T.Buffer((128, 128), "float32")):
T.func_attr({"global_symbol": "mm_relu", "tir.noalias": True})
# with T.block("root"):
Y = T.alloc_buffer((128, 128))
for i, j_0, j_1, k in T.grid(128, 32, 4, 128):
with T.block("Y"):
vi = T.axis.spatial(128, i)
vj = T.axis.spatial(128, j_0 * 4 + j_1)
vk = T.axis.reduce(128, k)
T.reads(A[vi, vk], B[vk, vj])
T.writes(Y[vi, vj])
with T.init():
Y[vi, vj] = T.float32(0)
Y[vi, vj] = Y[vi, vj] + A[vi, vk] * B[vk, vj]
for i, j in T.grid(128, 128):
with T.block("C"):
vi, vj = T.axis.remap("SS", [i, j])
T.reads(Y[vi, vj])
T.writes(C[vi, vj])
C[vi, vj] = T.max(Y[vi, vj], T.float32(0))
# 还可以更换循环次序
# sch.reorder(j0, k, j1)此外,块之间也可以通过变换完成组合
# 将块C放到Y的内循环中
block_C = sch.get_block("C", "mm_relu")
# 感觉意思是将块C与j0循环绑定,及j0这个空间轴变换时,原本只有Y有动作,现在C也有动作
sch.reverse_compute_at(block_C, j0)
IPython.display.Code(sch.mod.script(), language="python")
@I.ir_module
class Module:
@T.prim_func
def mm_relu(A: T.Buffer((128, 128), "float32"), B: T.Buffer((128, 128), "float32"), C: T.Buffer((128, 128), "float32")):
T.func_attr({"global_symbol": "mm_relu", "tir.noalias": True})
# with T.block("root"):
Y = T.alloc_buffer((128, 128))
for i, j_0 in T.grid(128, 32):
for k, j_1 in T.grid(128, 4):
with T.block("Y"):
vi = T.axis.spatial(128, i)
vj = T.axis.spatial(128, j_0 * 4 + j_1)
vk = T.axis.reduce(128, k)
T.reads(A[vi, vk], B[vk, vj])
T.writes(Y[vi, vj])
with T.init():
Y[vi, vj] = T.float32(0)
Y[vi, vj] = Y[vi, vj] + A[vi, vk] * B[vk, vj]
for ax0 in range(4):
with T.block("C"):
vi = T.axis.spatial(128, i)
# 注意这里vj的变化,原本vj = j = j_0 * 4 + j_1,现在变成了j_0 * 4 + ax0
# 感觉是因为上面 reverse_compute_at 只是将C与j0绑定,所以j_1这个循环还是在Y中,C里还需要单独循环ax0
vj = T.axis.spatial(128, j_0 * 4 + ax0)
T.reads(Y[vi, vj])
T.writes(C[vi, vj])
C[vi, vj] = T.max(Y[vi, vj], T.float32(0))
此外还介绍了另一种原语decompose_reduction,用于将语块中元素的初始化与规约更新分开: 这也是 TVM 在以后编译的时候隐式做的,所以这一步的主要目的是让它显式,看看最终效果
# 将块Y中的初始化与循环k无关(k是规约轴)
sch.decompose_reduction(block_Y, k)
IPython.display.Code(sch.mod.script(), language="python")
def lnumpy_mm_relu_v3(A: np.ndarray, B: np.ndarray, C: np.ndarray):
Y = np.empty((128, 128), dtype="float32")
for i in range(128):
for j0 in range(32):
# Y_init
for j1 in range(4):
j = j0 * 4 + j1
# 此时初始化在k循环之前就已经做好
Y[i, j] = 0
# Y_update
for k in range(128):
for j1 in range(4):
j = j0 * 4 + j1
Y[i, j] = Y[i, j] + A[i, k] * B[k, j]
# C
for j1 in range(4):
j = j0 * 4 + j1
C[i, j] = max(Y[i, j], 0)
c_np = np.empty((128, 128), dtype=dtype)
lnumpy_mm_relu_v3(a_np, b_np, c_np)
np.testing.assert_allclose(c_mm_relu, c_np, rtol=1e-5)构建与运行#
# 使用llvm将模型编译到本机平台
rt_lib = tvm.build(MyModule, target="llvm")
# 用于存储输入和输出的TVM NDArray
a_nd = tvm.nd.array(a_np)
b_nd = tvm.nd.array(b_np)
c_nd = tvm.nd.empty((128, 128), dtype="float32")
# 调用编译好的函数
func_mm_relu = rt_lib["mm_relu"]
func_mm_relu(a_nd, b_nd, c_nd)
# 将TVM与numpy的结果进行比较
np.testing.assert_allclose(c_mm_relu, c_nd.numpy(), rtol=1e-5)
# 调用TVM变换后的函数,继续比较
rt_lib_after = tvm.build(sch.mod, target="llvm")
rt_lib_after["mm_relu"](a_nd, b_nd, c_nd)
np.testing.assert_allclose(c_mm_relu, c_nd.numpy(), rtol=1e-5)在最后的结果中,TVM变换后的函数运行时间相比原先的TVM函数大幅缩短,为什么不同的循环变体会导致不同的时间性能呢?
关键在于CPU的访存策略,由于局部性原理,CPU在读取内存某元素时会尝试将该元素附近的元素一起获取到缓存中(cache块?特么OS快忘干净了😅)。因此具有连续内存访问的代码通常比随机访问内存不同部分的代码更快。
3. 端到端的模型执行#
现在考虑一个基础的两层神经网络,由2个MLP和1个relu组成(简化问题,删除最后的softmax)
numpy实现:
def numpy_mlp(data, w0, b0, w1, b1):
lv0 = data @ w0.T + b0
lv1 = np.maximum(lv0, 0)
lv2 = lv1 @ w1.T + b1
return lv2
res = numpy_mlp(img.reshape(1, 784),
mlp_params["w0"],
mlp_params["b0"],
mlp_params["w1"],
mlp_params["b1"])底层实现:
def lnumpy_linear0(X: np.ndarray, W: np.ndarray, B: np.ndarray, Z: np.ndarray):
Y = np.empty((1, 128), dtype="float32")
for i in range(1):
for j in range(128):
for k in range(784):
if k == 0:
Y[i, j] = 0
Y[i, j] = Y[i, j] + X[i, k] * W[j, k]
for i in range(1):
for j in range(128):
Z[i, j] = Y[i, j] + B[j]
def lnumpy_relu0(X: np.ndarray, Y: np.ndarray):
for i in range(1):
for j in range(128):
Y[i, j] = np.maximum(X[i, j], 0)
def lnumpy_linear1(X: np.ndarray, W: np.ndarray, B: np.ndarray, Z: np.ndarray):
Y = np.empty((1, 10), dtype="float32")
for i in range(1):
for j in range(10):
for k in range(128):
if k == 0:
Y[i, j] = 0
Y[i, j] = Y[i, j] + X[i, k] * W[j, k]
for i in range(1):
for j in range(10):
Z[i, j] = Y[i, j] + B[j]
def lnumpy_mlp(data, w0, b0, w1, b1):
lv0 = np.empty((1, 128), dtype="float32")
lnumpy_linear0(data, w0, b0, lv0)
lv1 = np.empty((1, 128), dtype="float32")
lnumpy_relu0(lv0, lv1)
out = np.empty((1, 10), dtype="float32")
lnumpy_linear1(lv1, w1, b1, out)
return out
result =lnumpy_mlp(
img.reshape(1, 784),
mlp_params["w0"],
mlp_params["b0"],
mlp_params["w1"],
mlp_params["b1"])
pred_kind = result.argmax(axis=1)
print("Low-level Numpy MLP Prediction:", class_names[pred_kind[0]])该模型的TVMScript实现:
@tvm.script.ir_module
class MyModule:
@T.prim_func
def relu0(x: T.handle, y: T.handle):
n = T.int64()
X = T.match_buffer(x, (1, n), "float32")
Y = T.match_buffer(y, (1, n), "float32")
for i, j in T.grid(1, n):
with T.block("Y"):
vi, vj = T.axis.remap("SS", [i, j])
Y[vi, vj] = T.max(X[vi, vj], T.float32(0))
@T.prim_func
def linear0(x: T.handle,
w: T.handle,
b: T.handle,
z: T.handle):
m, n, k = T.int64(), T.int64(), T.int64()
X = T.match_buffer(x, (1, m), "float32")
W = T.match_buffer(w, (n, m), "float32")
B = T.match_buffer(b, (n, ), "float32")
Z = T.match_buffer(z, (1, n), "float32")
Y = T.alloc_buffer((1, n), "float32")
for i, j, k in T.grid(1, n, m):
with T.block("Y"):
vi, vj, vk = T.axis.remap("SSR", [i, j, k])
with T.init():
Y[vi, vj] = T.float32(0)
Y[vi, vj] = Y[vi, vj] + X[vi, vk] * W[vj, vk]
for i, j in T.grid(1, n):
with T.block("Z"):
vi, vj = T.axis.remap("SS", [i, j])
Z[vi, vj] = Y[vi, vj] + B[vj]
@R.function
def main(x: R.Tensor((1, "m"), "float32"),
w0: R.Tensor(("n", "m"), "float32"),
b0: R.Tensor(("n", ), "float32"),
w1: R.Tensor(("k", "n"), "float32"),
b1: R.Tensor(("k", ), "float32")):
m, n, k = T.int64(), T.int64(), T.int64()
with R.dataflow():
lv0 = R.call_dps_packed("linear0", (x, w0, b0), R.Tensor((1, n), "float32"))
lv1 = R.call_dps_packed("relu0", (lv0, ), R.Tensor((1, n), "float32"))
out = R.call_dps_packed("linear0", (lv1, w1, b1), R.Tensor((1, k), "float32"))
R.output(out)
return out引入了一个新的 @R.function 即Relex函数,是一种表示上层神经网络执行的全新抽象
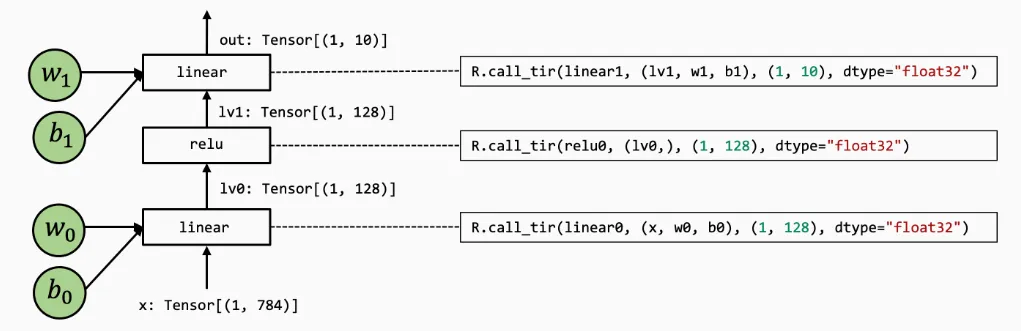
注意到,其中call_dps_packed将我们的元函数嵌入到计算图中,其主要作用是满足目标传递的调用约定,即 pure 或 side-effect free ,函数只从其输入中读取数据并输出返回结果,而不改变程序的其他部分,这可以方便我们隐藏调用底层元函数的细节
如果只是像numpy实现中那样:
lnumpy_linear0(data, w0, b0, lv0)
lnumpy_relu0(lv0, lv1)
lnumpy_linear1(lv1, w1, b1, out)计算图可能会变成这样:lv0既是lnumpy_linear0的入参,也是lnumpy_relu0的入参,其余同理
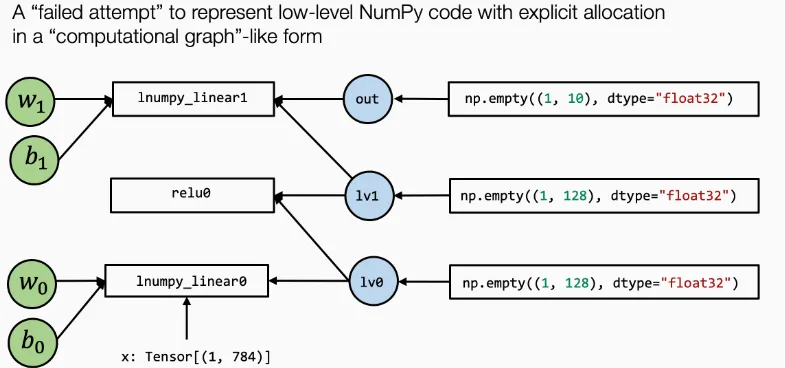
计算图通常具有以下性质:
- 框的每个输入边对应于操作的输入
- 每个出边对应于操作的输出
- 每个操作可以任意重新排序,直到边缘的拓扑顺序
当然,numpy的底层同样也使用了如lnumpy_call_dps_packed的类似调用
此外,注意with R.dataflow(): 是一个帮助我们标注程序计算图范围的方式,后面的构建运行就不多说了
4. 自动程序优化#
这一章主要讲随机调度变换,当我们无法决定原张量函数优化的每一个细节时,可以使用机器的一些随机变换做法
def stochastic_schedule_mm(sch: tvm.tir.Schedule):
block_C = sch.get_block("C", "main")
i, j, k = sch.get_loops(block=block_C)
# 注意 j_factors 没有使用固定的[none,4],而是采用随机值
j_factors = sch.sample_perfect_tile(loop=j, n=2)
j_0, j_1 = sch.split(loop=j, factors=j_factors)
sch.reorder(i, j_0, k, j_1)
sch.decompose_reduction(block_C, k)
return sch上述代码中,用到了 sch.sample_perfect_tile 来随机拆分循环。它会将输入的循环的长度进行随机分割,例如原始j =128 时,就可以分割为 [8,16]、[32,4]、[2,64] 等等,可以发现,每次运行时该函数的采样都不一样
此外还讲了一些随机搜索的东西,大概类似超参数的网格搜索之类的,在TVM里叫meta_schedule,主要还做了以下事情:
- 跨多个进程的并行基准测试
- 使用代价模型
cost model进行代价评估,这样可以避免每组都进行基准测试 - 根据历史轨迹来进行遗传搜索,而不是每次都随机采样
关键思想就是使用随机变换来指定好的程序的搜索空间,使用 tune_tir API 帮助在搜索空间内搜索并找到最优的调度变换
前面几章内容总结,就是为什么通过编译可以使模型运行更快(cache空间局部性),以及怎么样编译可以更快(元张量函数变换),同时也介绍了一些随机变换的方法(网格搜索),感觉随机变换的算法才是MLC性能的核心,也就是自动调优,TVM后面似乎用到了一些 autoTVM、autoSchedule 之类的方法进行 auto tune,这也是我需要重点关注的部分
5. 与机器学习框架的整合#
如何将机器学习模型从现有框架引入MLC,一些API的基础教程,参考 https://mlc.ai/zh/chapter_integration/index.html ↗
6. GPU硬件加速#
在GPU环境下的MLC流程,第一部分主要讨论CUDA,第二部分讨论专门的GPU环境,后面再看吧
7. 计算图优化#
提供了一些算子融合的基础代码,也不太想看